
Репликация master slave позволяет обеспечить системе надежность и гарантирует ее работоспособность при выходе из строя основного сервера БД.
Репликация базы данных это прием, применяемый в архитектуре информационных систем, результатом применения которого является распределение нагрузки при работе с одной базой данных на несколько серверов. В MySQL репликация Master-Slave используется чаще, но применяется и второй тип репликации — Master-Master.
Репликация Master-Slave предполагает дублирование данных на подчиненный сервер MySQL, производится подобное дублирование с целью обеспечения надежности. В случае выхода из строя Master сервера его функции переключаются на Slave.
Настройка MASTER SLAVE репликации в Debian
Будем использовать два сервера с адресами:
- Master сервер 192.168.0.1
- Slave сервер 192.168.0.2
Для демонстрации используются VDS объединенные в локальную сеть.
Чтобы всегда наверняка знать на каком сервере мы выполняем ту или иную команду отредактируем файлы /etc/hosts на обоих серверах
mcedit /etc/hosts
192.168.0.1 master
192.168.0.2 slave
Заменим существующие значения в /etc/hostname на master и slave соответственно, чтобы изменения вступили в силу сервера перезагрузим.
1. Производим настройки на мастер сервере.
root@master:/#
Редактируем основной конфигурационный файл сервера баз данных
mcedit /etc/mysql/my.cnf
Выбираем ID сервера — число можно указать любое, по умолчанию стоит 1 — строку достаточно раскомментировать
server-id = 1
Задаем путь к бинарному логу — также указано по умолчанию, раскомментируем
log_bin = /var/log/mysql/mysql-bin.log
Задаем название базы данных, которую будем реплицировать на другой сервер
binlog_do_db = db1
Перезапускаем Mysql чтобы конфигурационный файл считался и изменения вступили в силу:
/etc/init.d/mysql restart
2. Задаем пользователю необходимые права
Заходим в консоль сервера баз данных:
mysql -u root -p
Даем пользователю на подчиненном сервере необходимые права:
GRANT REPLICATION SLAVE ON *.* TO 'slave_user'@'%' IDENTIFIED BY '123';
FLUSH PRIVILEGES;
Блокируем все таблицы в БД
USE db1;
FLUSH TABLES WITH READ LOCK;
Проверяем статус Master-сервера:
SHOW MASTER STATUS;
+——————+———-+—————+——————+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+——————+———-+—————+——————+
| mysql-bin.000001 | 327 | db1 | |
+——————+———-+—————+——————+
1 row in set (0.00 sec)
3. Создаем дамп базы данных на сервере
Создаем дамп базы данных:
mysqldump -u root -p db1 > db1.sql
Разблокируем таблицы в консоли mysql:
mysql -u root -p
UNLOCK TABLES;
4. Переносим дамп базы на Slave-сервер
scp db1.sql root@123.123.123.123:/home
Дальнейшие действия производим на Slave-сервере
root@slave:/#
5. Созданием базу данных
mysql -u root -p
CREATE DATABASE db1;
Загружаем дамп:
cd /home
mysql -u root -p db1 < db1.sql
6. Вносим изменения в my.cnf
mcedit /etc/mysql/my.cnf
Назначаем ID инкрементируя значение установленное на Master сервере
server-id = 2
Задаем путь к relay логу
relay-log = /var/log/mysql/mysql-relay-bin.log
и путь bin логу на Master сервере
log_bin = /var/log/mysql/mysql-bin.log
Указываем базу
binlog_do_db = db1
Перезапускаем сервис
/etc/init.d/mysql restart
7. Задаем подключение к Master серверу
mysql -u root -p
CHANGE MASTER TO MASTER_HOST='192.168.0.1', MASTER_USER='slave_user', MASTER_PASSWORD='123', MASTER_LOG_FILE = 'mysql-bin.000001', MASTER_LOG_POS = 327;
Запускаем репликацию на подчиненном сервере:
START SLAVE;
Проверить работу репликации на Slave можно запросом:
SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.0.1
Master_User: slave_user
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000002
Read_Master_Log_Pos: 107
Relay_Log_File: mysql-relay-bin.000003
Relay_Log_Pos: 253
Relay_Master_Log_File: mysql-bin.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 107
Relay_Log_Space: 555
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
1 row in set (0.00 sec)
Поскольку каких-либо ошибок не возникло можно сделать вывод о том, что репликация настроена корректно. Настройка завершена.
Распределение запросов на чтение и запись по разными серверам, включенным в процесс репликации
Репликация может осуществляться и с целью повышения производительности системы, однако производительность здесь практически всегда вторична.
При работе приложения с БД самыми частыми операциями являются операции SELECT — запросы на считывание данных, модификация данных — запросы DELETE, INSERT, UPDATE, ALTER статистически происходит гораздо реже.
Чтобы в случае выхода из строя одного из серверов не произошло потери данных операции на изменение информации в таблицах всегда обрабатываются Master-сервером. Затем изменения реплицируются на Slave. Считывание же можно производить с сервера играющего роль Slave.
За счет этого можно получить выигрыш в производительности вместе с надежностью.
Решение популярно, но не всегда применимо поскольку при репликации могут наблюдаться задержки — если такое случается считывать информацию также приходится с Master-сервера.
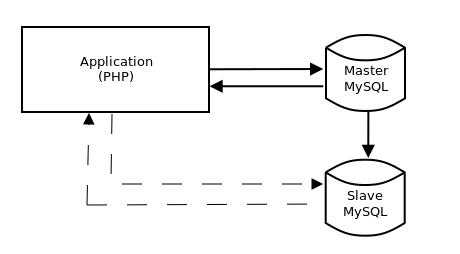
Направление запросов определенного типа к тому или иному серверу баз данных реализуется на уровне приложения.
Если выполнять разделение SELECT запросов и всех остальных на программном уровне отправляя их на нужный сервер — при выходе из строя одного из них приложение, которое обслуживает инфраструктура, окажется неработоспособно. Чтобы это работало нужно предусматривать более сложную схему и резервировать каждый из серверов.
Репликация применяется для отказоустойчивости, не для масштабирования
MASTER SLAVE репликация является хорошим инструментом обеспечения отказоустойчивости, в качестве главного минуса имеет рассинхронизацию копирования данных и задержки, которые могут быть критичны.
Полностью их избежать позволяет использование более современного решения Galera Cluster. Оно отличается простой настройкой, надежностью и отсутствием необходимости вручную копировать SQL дампы баз данных.