
Мониторинг дисков в Linux и отслеживание производительности обычно производится при помощи систем, основанных на готовых решениях таких как Zabbix.
Также для собственной инфраструктуры можно написать свои скрипты, которые будут производить мониторинг дисков, затем обрабатывать эти данные и при необходимости визуализировать.
В первой части статьи разберем популярные инструменты, во второй части будет скрипт на основе которого можно построить собственную минималистичную систему мониторинга.
Виртуальный или физический сервер
Рассматриваем мониторинг дисков в Linux принимая во внимание производительность и нагрузку на дисковую подсистему. Такой сценарий подходит если используются виртуальные или облачные ресурсы.
В случае с физическими серверами может потребоваться также утилита smarttools и проверка с помощью smart. Она показывает износ, температуру и другие параметры физических дисков. Такая проверка запускается обычно по CRON раз в сутки. Ссылка на статью про настройку CRON приведена в конце статьи.
Утилиты для мониторинга производительности дисков Linux сервера и нагрузки на них
Чаще всего применяются консольные утилиты vmstat, top, iotop, iostat и т.п. вывод некоторых из них — в частности, vmstat удобно парсится и и используется в bash скриптах.
vmstat
В выводе для отслеживания состояния дисков значение имеет блок io (характеризует операции ввода-вывода — их количество и затратность для системы )
io:
bi — blocks in — сколько блоков записали в дисковую систему
bo — blocks out — сколько считали
top
Нажатие D покажет список процессов создающих самую большую нагрузку на диск
iotop
Интерес представляют параметры о количестве процессов записи на диск и чтения с диска
Total DISK READ Total DISK WRITE
Total — показывает пропускную способность между ядром ОС и системой ввода-вывода
Actual DISK READ Actual DISK WRITE
Actual — показывает как система ввода-вывода обращается к железу
ionice:
—idle — процесс может использовать диск только если он простаивает и другими процессами не используется
—be — best effort (классы 0-7) — средний приоритет
—rt — real time — наивысший приоритет (классы 0-7, 7-й будет означать максимальный приоритет)
В некоторых случаях приоритет потребления диска для процессов требуется понизить, делается это как раз при помощи ionice
iostat входит в пакет sysstat — если в системе его нет, пакет можно установить при помощи apt-get
Большое количество полезной информации выведет вызов команды с ключом -x
iostat -x
Утилита SAR обладает широким функционалом и применяется, среди прочего, и для мониторинга дисков
sar является частью пакета sysstat. Чтобы запустить 2 теста параметров с интервалом в 5 секунд нужно выполнить sar 5 2
Используя ключ -b можно получить информацию о подсистеме ввода-вывода и использовании буферов
sar -b 5 2
Linux 4.4.0-97-generic (admin-Satellite-C660) 28.10.2017 _i686_ (4 CPU)
14:54:02 tps rtps wtps bread/s bwrtn/s
14:54:07 3,80 0,00 3,80 0,00 307,20
14:54:12 0,40 0,00 0,40 0,00 12,80
Average: 2,10 0,00 2,10 0,00 160,00
В выводе будут следующие параметры с актуальными значениями:
- %busy (процент занятости),
- avque (средня длина очереди),
- r+w/s (число операций чтения и записи в секунду),
- blks/s (число переданных блоков в секунду),
- avwait (среднее время ожидания)
- avserv (среднее время обслуживания).
Большие значения %busy и avque будут говорить о существовании проблем с дисковой подсистемой.
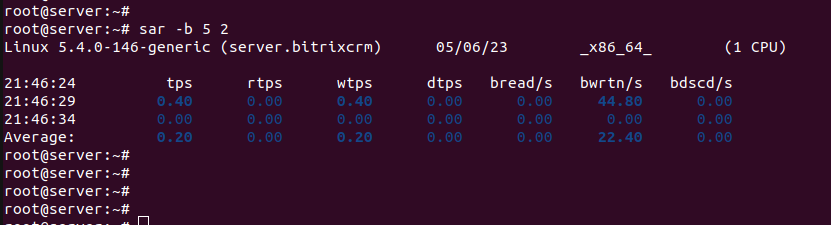
С опцией -d будет выводиться информация по системным устройствам, -p (pretty) сделает вывод более читабельным
sar -d -p 5 2
Linux 5.4.0-146-generic (server.bitrixcrm) 05/06/23 x86_64 (1 CPU)
21:46:24 tps rtps wtps dtps bread/s bwrtn/s bdscd/s
21:46:29 0.40 0.00 0.40 0.00 0.00 44.80 0.00
21:46:34 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: 0.20 0.00 0.20 0.00 0.00 22.40 0.00
Пример результата выполнения:
Скрипт, осуществляющий проверку дисков
Рассмотрим простейший скрипт, который будет контролировать количество операций ввода-вывода и в случае превышения установленного значения отправлять письма на адрес администратора сервера.
Скрипт будет контролировать только два параметра, это простейшая реализация. Однако добавив некоторый функционал и дополнительные параметры скрипт можно использовать для построения собственной системы мониторинга.
Будем парсить вывод vmstat, понадобятся значения bi и bo, которые показывают сколько операций ввода-вывода выполняется дисковой подсистемой.
$ vmstat
procs ————memory———- —swap— ——io—- -system— ——cpu——
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 1 832180 189268 67288 649176 1 18 34 38 158 778 8 2 88 2 0
Оставим в выводе только интересующие нас колонки
$ vmstat | awk '{print $9, $10}'
bi bo
34 38
При помощи tail вырежем последнюю строку со значениями
vmstat | awk '{print $9, $10}' | tail -1
43 45
Мониторинг дисков в Linux с помощью скрипта.
Далее приведены строки скрипта, который будет использоваться и пояснения.
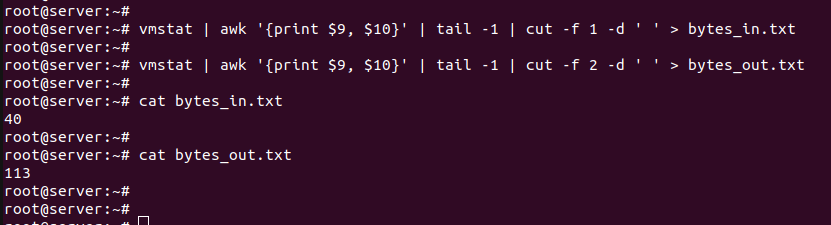
Значение первого параметра будем записывать в файл bytes_in.txt
vmstat | awk '{print $9, $10}' | tail -1 | cut -f 1 -d ' ' > bytes_in.txt
Значение второго таким же образом в bytes_out.txt
vmstat | awk '{print $9, $10}' | tail -1 | cut -f 2 -d ' ' > bytes_out.txt
Результат и содержимое файлов приведено на скриншоте:
Возьмем в качестве предельного значение 90, которое не является критичным даже для десктоп инсталяции и в настоящей системе может быть заменено на любое другое.
Читаем значение из файла и сравниваем его с числом 90, если значение больше 90 — отправляем письмо на адрес электронной почты администратора
if [ `cat /home/admin/bytes_in.txt` -gt 90 ]; then echo 'Value of bytes_in is greater then 90. Take a look' | mail -s ' WARNING' admin@example.com; fi
if [ `cat /home/admin/bytes_out.txt` -gt 90 ]; then echo 'Value of bytes_out is greater then 90. Take a look' | mail -s 'WARNING' admin@example.com; fi
Получили скрипт в 4 строки, который будет контролировать самые важные параметры работы дисковой подсистемы сервера.
Последние 2 можно выполнять с небольшой задержкой, которая реализуется через sleep
sleep 2;
Получившиеся пять строк нужно добавить в CRON, если задание будет выполняться раз в минуту — администратор всегда будет в курсе возникающих проблем с вводом-выводом.
Таким же образом можно контролировать значение других параметров.
Можно включать в письмо актуальное значение на которое среагировал мониторинг. Нужно ли это следует решать каждый раз индивидуально.
Читайте про то как создавать и запускать bash скрипты.